Athena 建立資料庫小記
今天來寫已經有既有資料
如何建立 Athena 資料庫以及簡單查詢
==== 資料說明 ====
使用資料 Verizon CDN log
log 的欄位如下
timestamp time-taken c-ip filesize s-ip s-port sc-status sc-bytes cs-method cs-uri-stem - rs-duration rs-bytes c-referrer c-user-agent customer-id x-ec_custom-1
內容範例如下
1576715463 1100 180.217.136.201 2423508 142.189.104.145 443 TCP_MISS/200 2424002 GET http://wac.0001.<Domain>/000001/SWF_Verification/myplayer.swf - 1150 2425404 "-" "stagefright/1.2 (Linux;Android 9)" 446510 "-"
Date/Time (timestamp)
Time Taken (time-taken)
Client IP Address (c-ip)
File Size (filesize)
Edge Server IP Address (s-ip)
Edge Server Port (s-port)
[Cache and HTTP] Status Codes (sc-status)
Bytes Sent (sc-bytes)
HTTP Method (cs-method)
Request URL (cs-uri-stem)
-
Remote Server Time Taken (rs-duration)
Remote Server - Bytes Sent (rs-bytes)
Referrer (c-referrer)
User Agent (c-user-agent)
Customer Account Number (customer-id)
Custom Log Field 1 (x-ec_custom-1)
主要分隔的符號有兩種
空白鍵
雙引號
==== 建立 Athena ====
登入到 AWS console
將檔案上傳到 s3
s3://maxtest20201121/
Region: Tokyo
登入 Athena console
建立資料庫
可以先確認目前的 DB
下拉檢查 Database 目前有哪些

在 Query editor 頁面
輸入
create database testdb20201121;
點選 Run query
確認相關資訊
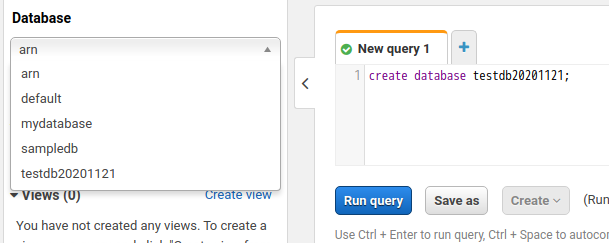
這邊可以看到 testdb20201121 已經被建立, 還有剛剛建立的語句
接下來建立 Table
先點選剛剛建立的 testdb20201121 切換到該 Database
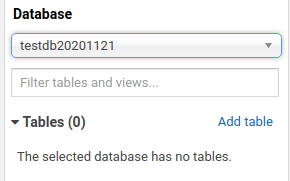
確認目前沒有 table
參考 AWS 提供的資訊來建立 Table
基本上, 要分為有分區以及不分區的狀況, 因為是實驗, 所以採取不分區的方式來實作
CREATE EXTERNAL TABLE tvcdn_no_partition (
timestamp string,
time_taken string,
c_ip string,
filesize string,
s_ip string,
s_port string,
sc_status string,
sc_bytes string,
cs_method string,
cs_uri_stem string,
hyphen string,
rs_duration string,
rs_bytes string,
c_referrer string,
c_user_agent string,
customer_id string,
x_ec_custom_1 string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'escapeChar' = '\\',
'quoteChar' = '"',
'separatorChar' = ' ')
LOCATION
's3://maxtest20201116/';
資料表的名稱不支援特殊字元, 除了底線以外, 可以參考 https://docs.aws.amazon.com/zh_tw/athena/latest/ug/tables-databases-columns-names.html 所以欄位名稱如果有 - 連接符號 就要換成 _ , 而且也沒有辦法單獨用 _ 來當欄位名稱, 所以我用 hyphen 來代替.
後面類型的部分會先全部用 string 來定義, 因為避免發生相關錯誤.
s3 的路徑如果是 bucket name一定要 / 結尾, 不然會得到錯誤訊息 java.lang.IllegalArgumentException: Can not create a Path from an empty string
s3 的路徑如果是目錄就不用 / 結尾, 但是最好還是 / 結尾
觀察相關資訊
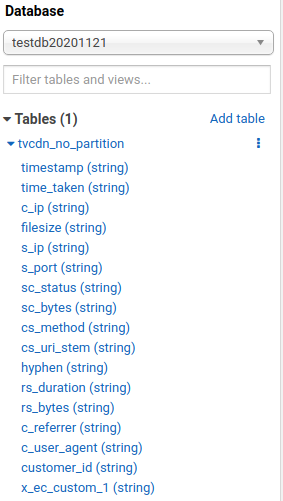
這邊可以看到 Table 已經被建立起來
接下來測試相關查詢
Lab1: 取出 20 筆資料
輸入
select * from tvcdn_no_partition limit 20
點選 Run query
取出 table 內 20 筆資料
觀察相關結果

Lab2: 統計 URL 被要求的次數與頻寬
輸入
-- 統計 URL 被要求的次數與頻寬
SELECT cs_uri_stem,
-- 使用 count 來算 cs_uri_stem (Request URL)次數, 然後別名爲 requests
count(*) AS requests,
-- cast 是用來轉型, sc_bytes ( server to client - Sent Bytes ) 轉成 bigint 類型, 除以2次的 1024, 轉化爲 MB 大小, 然後別名爲 MB
sum(cast(sc_bytes AS bigint))/1024/1024 AS MB
-- 資料來源的 DB 與 table
FROM "testdb20201121"."tvcdn_no_partition"
-- 因為 sc_bytes 內有 - , 會讓轉型失敗, 所以使用 WHERE 加上 NOT IN 排除 資料裡面有 -
WHERE sc_bytes NOT IN ('-')
GROUP BY cs_uri_stem
-- 使用 requests 排序, 用降冪排序
ORDER BY requests desc
-- 只取前 50 名
limit 50
觀察相關資訊

Lab 3: 統計 Client IP Top 50 要求次數與頻寬
輸入
-- 統計 Client IP Top 50 要求次數與頻寬
SELECT c_ip , count(c_ip) as requests,
-- cast 是用來轉型, sc_bytes ( server to client - Sent Bytes ) 轉成 bigint 類型, 除以2次的 1024, 轉化爲 MB 大小, 然後別名爲 MB
sum(cast(sc_bytes AS bigint))/1024/1024 AS MB
-- 資料來源的 DB 與 table
FROM "testdb20201121"."tvcdn_no_partition"
-- 因為 sc_bytes 內有 - , 會讓轉型失敗, 所以使用 WHERE 加上 NOT IN 排除 資料裡面有 -
WHERE sc_bytes NOT IN ('-')
GROUP BY c_ip
ORDER BY requests desc
limit 50
觀察相關資訊

這樣也算是往 AWS 更進一步了
~ enjoy it
Reference:
沒有留言:
張貼留言